Contrastive Difference Predictive Coding

Abstract: Predicting and reasoning about the future lies at the heart of many time-series questions. For example, goal-conditioned reinforcement learning can be viewed as learning representations to predict which states are likely to be visited in the future. While prior methods have used contrastive predictive coding to model time series data, learning representations that encode long-term dependencies usually requires large amounts of data. In this paper, we introduce a temporal difference version of contrastive predictive coding that stitching together pieces of different time series data to decrease the amount of data required to learn to predict future events. We apply this representation learning method to derive an off-policy algorithm for goal-conditioned RL. Experiments demonstrate that, compared with prior RL methods, ours achieves higher success rates with less data, and can better cope with stochastic environments.
Evaluation on online GCRL benchmarks
Below, we show examples of TD InfoNCE solving state-based manipulation tasks in the paper, comparing to prior methods quasimetric RL and contrastive RL. In each video, the desired goal (red point) is set to the same position and we use the color of the border to indicate failure (red) and success (green).
TASK: reach
TASK: push
TASK: pick and place
TASK: slide
Evaluation on offline goal reaching
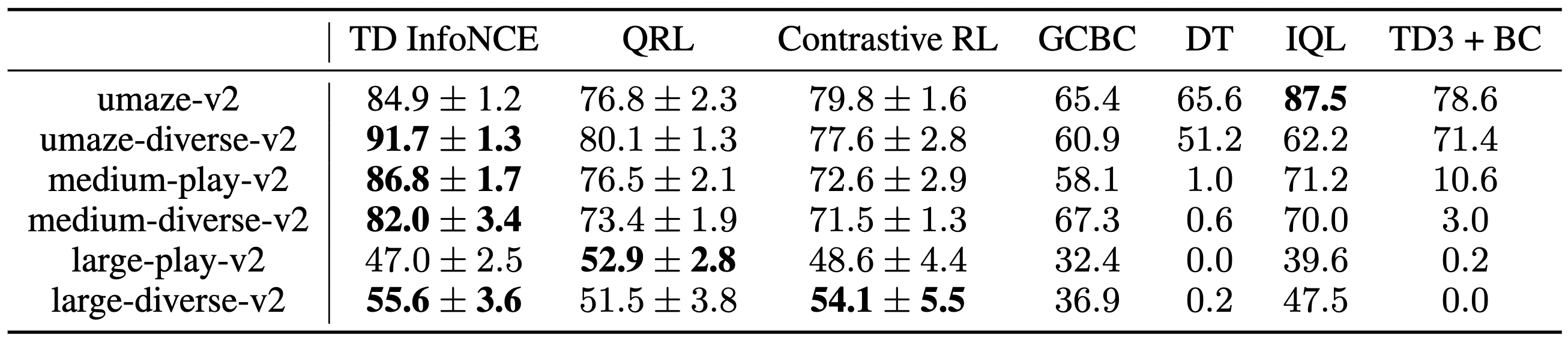
We evaluate TD InfoNCE on solving AntMaze tasks from the D4RL benchmark in the table below. TD InfoNCE outperforms most baselines on most tasks.
Off-policy reasoning
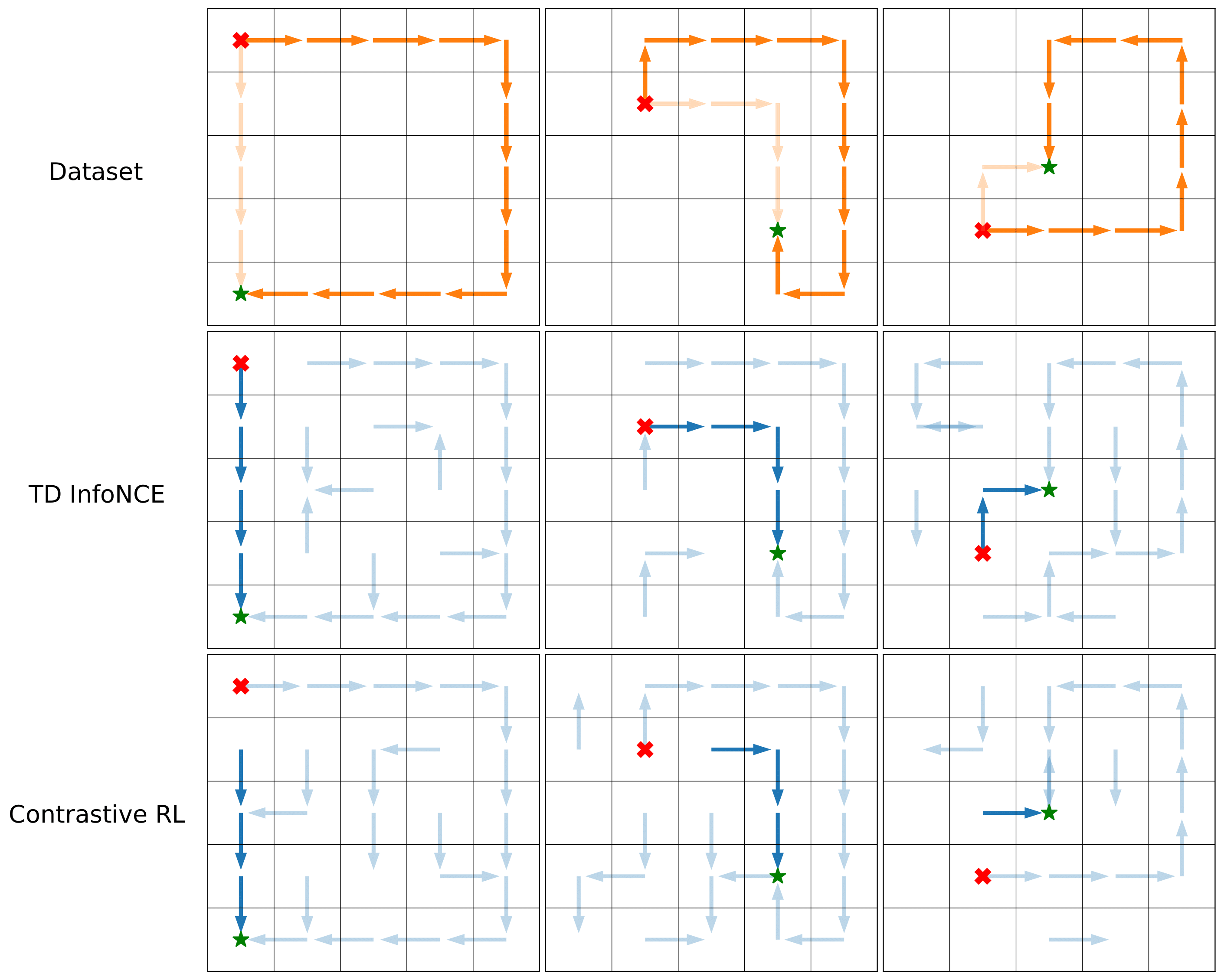
We conduct two experiments on a 5 x 5 discrete gridworld environment to study the capability of TD InfoNCE in performing dynamic programming.
Stitching trajectories in a dataset: The behavioral policy collects “Z” style trajectories.
Unlike the Monte Carlo method (contrastive RL) , TD InfoNCE successfully ‘‘stitches’’ these trajectories together, navigating between pairs of (start - red cross, goal - green star) states unseen in the training trajectories.
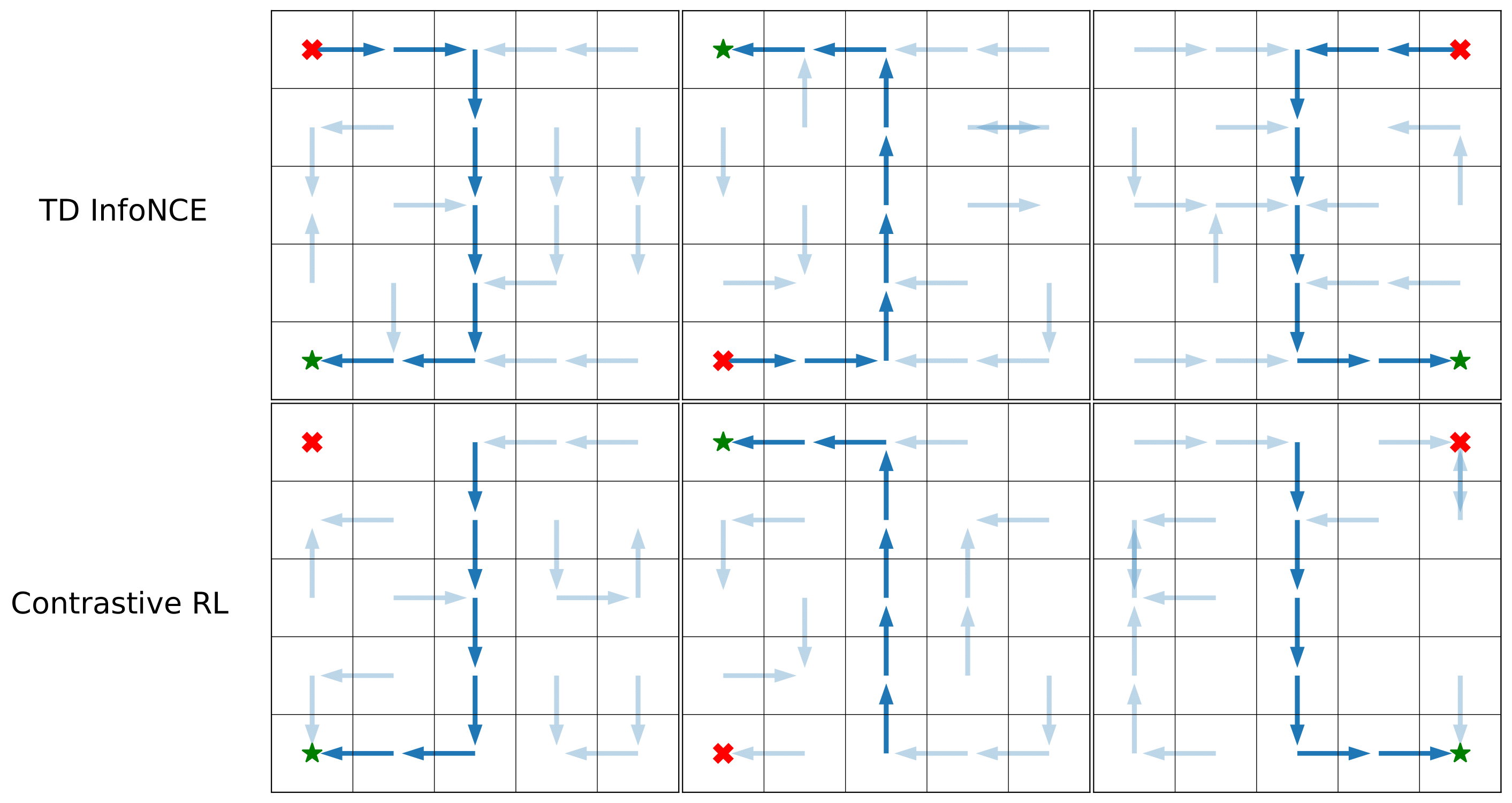
Searching for shortcuts in skewed datasets: Conditioned on different initial states (red cross) and goals (green star), we collect datasets with 95% long paths (dark) and 5% short paths (light). TD InfoNCE infers the shortest path, while contrastive RL fails to find this path.