Stabilizing Contrastive RL: Techniques for Robotic Goal Reaching from Offline Data
Ruslan Salakhutdinov, Sergey Levine
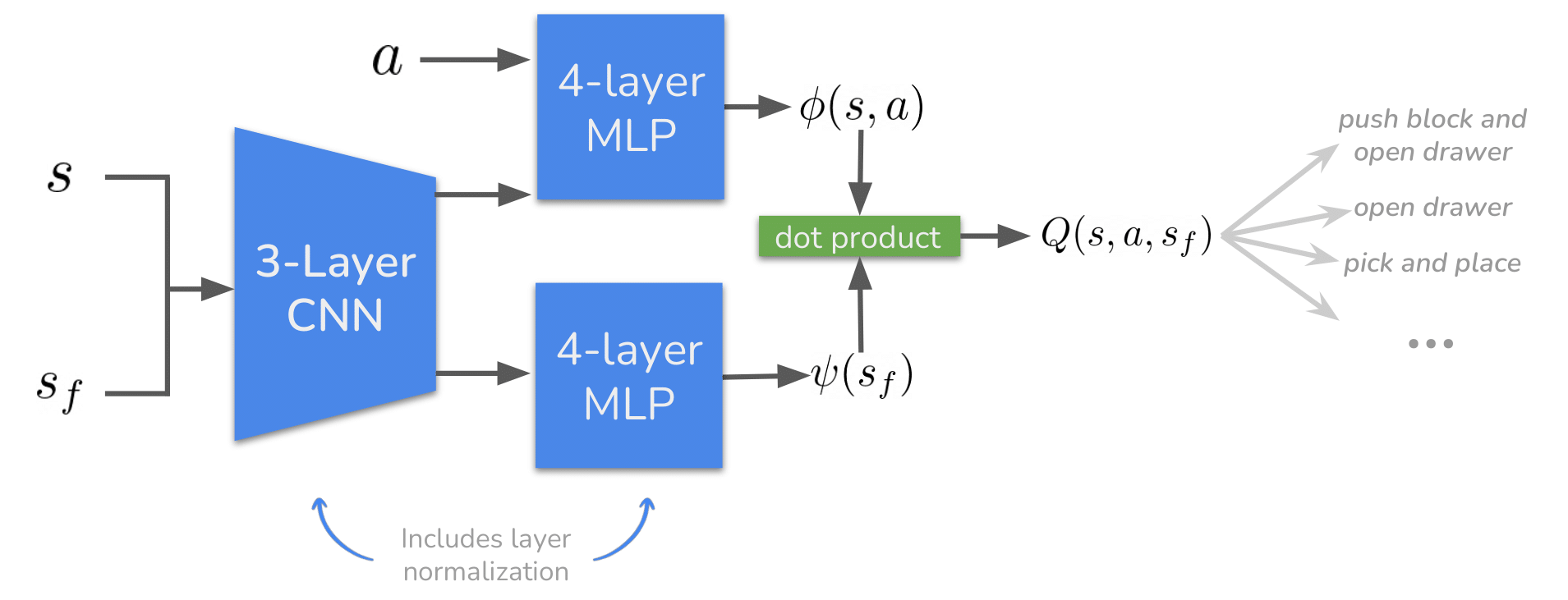
Abstract: Robotic systems that rely primarily on self-supervised learning have the potential to decrease the amount of human annotation and engineering effort required to learn control strategies. In the same way that prior robotic systems have leveraged self-supervised techniques from computer vision (CV) and natural language processing (NLP), our work builds on prior work showing that the reinforcement learning (RL) itself can be cast as a self-supervised problem: learning to reach any goal without human-specified rewards or labels. Despite the seeming appeal, little (if any) prior work has demonstrated how self-supervised RL methods can be practically deployed on robotic systems. By first studying a challenging simulated version of this task, we discover design decisions about architectures and hyperparameters that increase the success rate by 2x. These findings lay the groundwork for our main result: we demonstrate that a self-supervised RL algorithm based on contrastive learning can solve real-world, image-based robotic manipulation tasks, with tasks being specified by a single goal image provided after training.
Evaluation on Real Manipulation Tasks
Below, we show examples of the behavior learned by stable contrastive RL and baselines, GC-IQL and GCBC, on the real manipulation tasks. All the methods successfully solves the simplest tasks “reach the eggplant”, while stable contrastive RL achives 60% success rates on the other two tasks where baselines fail. Note that our method casts reinforcement learning as a self-supervised problem, without using any reward function and successfully solving multi-stage goal-conditioned control tasks.
TASK: Pick the red spoon and place it on the left of the pot.

TASK: Push the can to the wall.

TASK: Reach the eggplant on the table.

Evaluation on Simulated Manipulation Tasks
We also visualize examples of the behavior learned by stable contrastive RL and the same baselines on the simulated manipulation tasks. Stable contrastive RL is able to solve multi-stage goal-conditioned control tasks, while baselines complete single stage or fail to complete the tasks.
TASK: Pick the green object in the drawer, place it in the tray, and then close the drawer.

TASK: Push the orange block on the table and then open the drawer.

TASK: Pick the green object on the table and place it in the tray.

TASK: Close the drawer.

Failure Cases
For the task below, the agent tries to push the orange block, but fails to close the drawer.
TASK: Push the orange block on the table and then close the drawer.
